
Ich beschäftige mich seit 2018 intensiv mit den Grundlagen der Künstlichen Intelligenz. Mein Wissen hole ich mir bei verlässlichen Quellen wie dem Hasso-Plattner-Institut in Potsdam (https://hpi.de/), verschiedenen Instituten der Fraunhofer-Gesellschaft (https://www.iese.fraunhofer.de/blog/wie-funktionieren-llms/) oder öffentlich zugänglichen Kursen von Kammern (https://www.wko.at/veranstaltungen/b0f2a620-a987-4e96-9d36-3c5805ad1a0e) und außer-universitären Forschungs- und Entwicklungseinrichtungen (https://www.know-center.at/ki-verstehen-analysieren-und-optimal-nutzen/). Insgesamt habe ich einen guten Überblick über die Paradigmen, aktuelle Entwicklungen und Werkzeuge der Künstlichen Intelligenz (KI) im privaten und unternehmerischen Umfeld.
Mit diesem Artikel reaktiviere ich mein Wissen über Paradigmen, Methoden und Algorithmen künstlicher Intelligenz. Dafür nutze ich das von mir zusammengestellte Lehrmaterial für einen Kurs, den ich im Jahr 2020 für die Embedded Academy der eclipseina GmbH durchführen wollte. Ich wünsche Ihnen viel Spass beim Lesen und einen guten Erkenntnisgewinn!
Einleitung
Dieser Artikel gibt einen Überblick über häufig verwendete KI-Paradigmen, KI-Methoden und dahinter liegende Algorithmen und geeigneter Anwendungsbereiche. Er befasst sich nicht mit Lernmethoden, und auch nicht mit dem Bereitstellen von Daten für die KI-Modelle oder anverwandten Themen wie Compliance, Datenschutz und AI-Act. Die Leser sollen lediglich aus fachfremder Perspektive an das Thema KI herangeführt werden.
Ziel der Artikelserie ist es, die Allgemeinheit für KI zu begeistern. Das kann gelingen, wenn die Menschen die verschiedenen Algorithmen und Methoden der KI verstehen und diese auf Abläufe in ihrem Umfeld übertragen können.
Im einzelnen wird die Artikelserie dem Leser helfen,
- Begriffe der Künstlichen Intelligenz sicher anzuwenden
- die wesentlichen Paradigmen, Modelle und Verfahren zu unterscheiden
- Paradigmen auf Fragestellungen in Ihrem Unternehmen zu übertragen
- realistische Vorstellungen zu Einsatzmöglichkeiten und Grenzen der künstlichen Intelligenz zu entwickeln
Überblick über Paradigmen, Methoden und Modelle der künstlichen Intelligenz
Beginnen möchte ich meine Artikelserie mit einem Überblick über Paradigmen, Methoden und Modelle, die sich hinter dem Begriff der künstlichen Intelligenz verbergen. Ich nutzte dazu eine Übersicht, deren Urheberrechte bei @emiliyinamillion liegen und die weitreichende Verbreitung in der damaligen Forschungslandschaft erfuhr:

Das Schaubild zeigt eine mögliche Strukturierung von Paradigmen und Lernmethoden. Sie erhebt keinen Anspruch auf Vollständigkeit und wissenschaftliche Präzision. Es sei an dieser Stelle erwähnt, dass andere Quellen abweichende Einteilungen der Paradigmen nutzen und zum Beispiel zwischen Regression, Klassifizieren, Clustern und Frequent Itemset Mining unterscheiden. Auch fehlen in diesem Schaubild die Large Language Modelle (LLM). Ebenfalls ist die Zuordnung der Lernverfahren zu den jeweiligen Paradigmen zu hinterfragen. Insgesamt jedoch ist das Schaubild ein wichtiges Hilfsmittel für den Einstieg in das Fachgebiet „Künstliche Intelligenz“, denn es gibt Struktur und Hinweise zu typischen Fragestellen für die Paradigmen und Methoden der KI.
Populäre Paradigmen der KI sind Modelle zur Regression und zum Klassifizieren sowie Methoden zum Clustern, Assoziieren und Visualisieren von Datensätzen. Im folgenden werden die in Zusammenhang mit KI genutzten Modelle und Methoden vorgestellt, einschließlich der dahinter liegenden Wahrscheinlichkeitsmodelle und statistischen Verfahren.
Die wichtigsten Paradigmen, Methoden und Modelle der künstlichen Intelligenz im Einzelnen
Regressionsanalyse
Eine Regression beschreibt den kontinuierlichen (linearen oder logarithmischen) Zusammenhang zwischen Variablen. Regressionsanalysen sind also statistische Analysenverfahren, die die Beziehung zwischen einer abhängigen und weiteren unabhängigen Variablen modellieren. Aus mathematischer Sicht basieren Regressionsanalysen häufig auf der Methode der kleinsten Quadrate. Die Ausgabeparameter sind Elemente der reellen Zahlen.

Quelle: Vortragsunterlagen Embedded Academy ®, Dr. S. Kuske
Regressionsanalysen werden für bestimmte Fragestellungen zur Ermittlung wahrscheinlicher Werte genutzt. Ihre häufigste Anwendung sind Vorhersagemodelle (Prognosen).
Typische Beispiele sind der Zusammenhang von Körpergröße und Körpergewicht eines Menschen, der Preis eines Hauses in Abhängigkeit von der Lage oder die Vorhersage des Umsatzes mit einem bestimmten Artikel im nächsten Monat.
Klassifikation
Bei der Klassifikation werden Schlussfolgerungen aus Beobachtungen gezogen. Mathematisch betrachtet liegen hinter Klassifikationsfragen also Algorithmen aus dem Teilgebiet der Wahrscheinlichkeitsrechnung, die zur Einteilung von Objekten in Kategorien oder zum Erkennen von Mustern geeignet sind. Typische Algorithmen sind Decision Trees, Nearest-Neighbor-Algorithmen und Bayes-Klassifizierungen. Die Ausgabeparameter sind kategorisch (zum Beispiel Blau-Gelb-Rot).
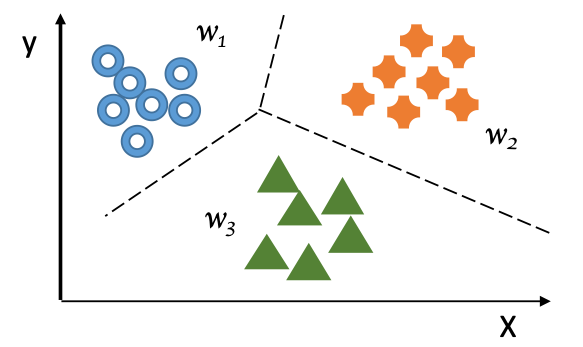
Quelle: Vortragsunterlagen Embedded Academy ®, Dr. S. Kuske
Klassifikationsalgorithmen werden in Vorhersagemodellen für die Zuordnung von Objekten zu einer oder mehreren Kategorien oder zur Einteilung von Daten anhand von Trainingsdaten und Klassifizierungsmerkmalen genutzt.
Typische Anwendungsbereiche der Decision Tree Algorithmen sind Vorhersagemodelle für die Vorratshaltung, zum Beispiel für verderbliche Waren in temporär betriebenen Bewirtungsstätten, die Grenzwertbestimmung zum Beispiel für den Zusatz kanzerogener Zusätze in Kosmetikartikel oder die Risikobestimmung zum Beispiel für die Einteilung von Versicherungskunden in Risikoklassen.
Nearest-Neighbor-Algorithmen werden typischerweise zum Erkennen und zur Abwehr von Bedrohungen eingesetzt, finden aber auch Einsatz bei typischen Vertriebsfragestellungen. Beispiel sind die Prognose von Einbruchsdelikten oder das Vorschlagswesen für alternative Immobilien eines potentiellen Hauskäufers.
Bayes-Klassifizierungen wiederum werden häufig im Bereich des Marketings eingesetzt. Sie sind geeignet, um Fragen zur Zielgruppenerweiterung zur Absatzsteigerung zu beantworten und die Preisgestaltung für Produktpakete zu entwickeln.
Gruppieren (Clustern)
Das Clustern ist eine allgemeine Methode zum Zusammenfassen von Objekten mit ähnlichen Eigenschaften in Gruppen in einer Art und Weise, die das Erkennen von Gemeinsamkeiten oder Beziehungen zwischen den Objekten ermöglicht. Das Ziel des Clustern ist die Einteilung von Objekten in Gruppen, wobei die Objekte innerhalb der Gruppe eine hohe Ähnlichkeit in bestimmten Merkmalen haben und sich zwischen den Gruppen jedoch größtmögliche Unterschiede zeigen.
Mathematisch wird die Varianz eines neuen Elements zu den Clusteroiden ermittelt und das Element dem Ergebnis entsprechend einer Gruppe (einem Cluster) zugeordnet.

Quelle: Vortragsunterlagen Embedded Academy ®, Dr. S. Kuske
Methoden zum Clustern von Objekten werden zum Erkennen von Zusammenhängen eingesetzt. Es handelt sich also um explorative Datenanalysen, die immer auch mit einer Verallgemeinerung einer Aussage verbunden sind.
Clustern ist unbewachtes Klassifizieren und wird als Stand-alone Verfahren zum Beispiel genutzt, um Versicherungsprämien in Abhängigkeit von bestimmten Merkmalen wie Alter, Geschlecht und Daten zur Unfallwahrscheinlichkeit festzulegen. Die Methode wird jedoch auch zur Aufbereitung von Daten für andere Verfahren wie zum Beispiel epidemiologische Studien genutzt.
Feature Reduction
Die Future Reduction ist ein Teilgebiet der Künstlichen Intelligenz, das im Wesentlichen ein Reduzieren der zu betrachtenden Variablen ohne Informationsverlust zum Ziel hat, um letztlich die Analysen zu beschleunigen, den benötigten Speicherplatz zu reduzieren und die Ergebnisse effizient zu visualisieren. Es ist ein Verfahren, das primär zum zum Aufbereiten von Daten angewandt wird.
Frequent Itemset Mining
Die Frequent Itemset Analyse ist eine Methode zur Extraktion versteckter Informationen aus Datensätzen, die zum Zweck dieser spezifischen Datenanalyse aufbereitet, mitunter aus verschiedenen Quellen zusammengeführt und in dedizierten in Data Marts zur Verfügung gestellt werden. So ein reduzierter Datensatz könnte zum Beispiel lediglich Daten von Kunden eines Supermarkts enthalten, die in Einpersonenhaushalten leben. Gesucht wird in den Daten nach regelmäßiger Beziehungen zwischen Objekten oderdem Auftreten gemeinschaftlich Ereignisse.
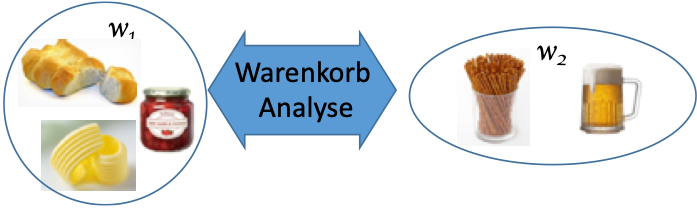
Quelle: Vortragsunterlagen Embedded Academy ®, Dr. S. Kuske
Typische Anwendungsbereiche sind Marketing (cross-selling, add-on-sales), Empfehlungsapplikationen oder web-log-Analysen.
Frequent Itemset Mining wird aber auch extensiv zur Erkennung von Anomalien eingesetzt (Outlier Mining). Typische Anwendungsfälle sind das Aufdecken vin Kreditkartenbetrug, die Rauschunterdrückung bei der Vorverarbeitung von Daten, die Kundensegmentierung für Marketing- oder Entwicklungsfragestellungen und die vorausschauende Wartung von Produktionsanlagen.
Neuronale Netze
Neuronale Netze gehören neben den Large-Language-Modellen (LLM) zu den bekanntesten Methoden der Künstlichen Intelligenz. Sie sind vielseitig einsetzbar – von der Bilderkennung über die Spracherkennung und Empfehlungsassistenten bis hin zu Prognosewerkzeugen.
Ganz hervorragendes Lehrmaterial zu den mathematischen Grundlagen, dem Aufbau und der Funktionsweise neuronaler Netze findet sich im Youtube-Kanal der 3Blue1Brown – Autorengruppe. An dieser Stelle sein auf das Tutorial „Aber was ist ein neuronales Netzwerk?“ verwiesen.

Die Anwendungsbereiche neuroyaler Netze sind vielfältig. Besonders geeignet sind sie als Unterstützung für die:
- Diagnose (Medizin, Qualitätsmanagement, Hohlraumanalyse)
- Prognose (Preisentwicklung am Finanzmarkt, Energieverbrauch)
- Mustererkennung
- Spracherkennung
Zusammenfassung
Dieser Artikel befasst sich mit einigen wichtigen Paradigmen, Methoden und Algorithmen der Künstlichen Intelligenz (KI) ohne Anspruch auf Vollständigkeit. Das wissenschaftliche Feld der KI ist wesentlich breiter gefächert, als es dieser Artikel darzustellen vermag. Ich hoffe jedoch, dass ich einen ersten Eindruck von der Vielfalt der Paradigmen, Methoden und Algorithmen der KI vermitteln konnte.
Ob Paradigmen der künstlichen Intelligenz für einen Business Use Case genutzt werden sollten, welche Methode oder welcher Algorithmus jeweils Anwendung findet, oder ob es eine Kombination von Verfahren braucht, um eine gegebene Fragestellung zu beantworten (=Modell), hängt ganz entscheidend von der Fragestellung an sich, der Komplexität der Aufgabenstellung, der Verfügbarkeit von Ressourcen, der Verfügbarkeit einer hinreichend großen, geeigneten Menge an relevanten Daten und dem Potential an Einsparungen, Erkenntnisgewinn oder der Generation sonstiger Wettbewerbsvorteile ab. Für gute Entscheidungen braucht es dazu Experten, die sich im weiten Feld der KI, Daten und Anwendungen auskennen und die richtigen Schritte zur richtigen Zeit machen.